
栈
1 概念
栈是我们做PWN时的一个十分重要的数据结构,栈区也是一个需要注意的内存区域
栈是一种数据结构,存放局部变量,从感性上说,可以想象成羽毛球筒,球只能从筒口插入,从筒口拿出
栈是由高地址向低地址生长
2 PUSH指令(字入栈)
格式:PUSH 源操作数(字)
1 | PUSH AX ;AX进栈 |
PUSH 指令首先减少 ESP 的值,再将源操作数复制到堆栈。操作数是 16 位的,则 ESP 减 2,操作数是 32 位的,则 ESP 减 4。PUSH 指令有 3 种格式:
1 | PUSH reg/mem16 |
注意:push指令不允许8位寄存器
高字节先进栈,低字节在栈顶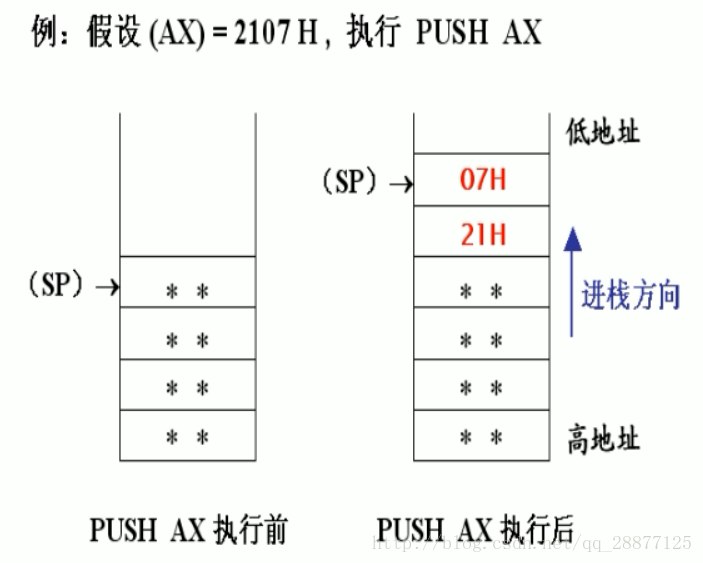
2.1 PUSHAD指令
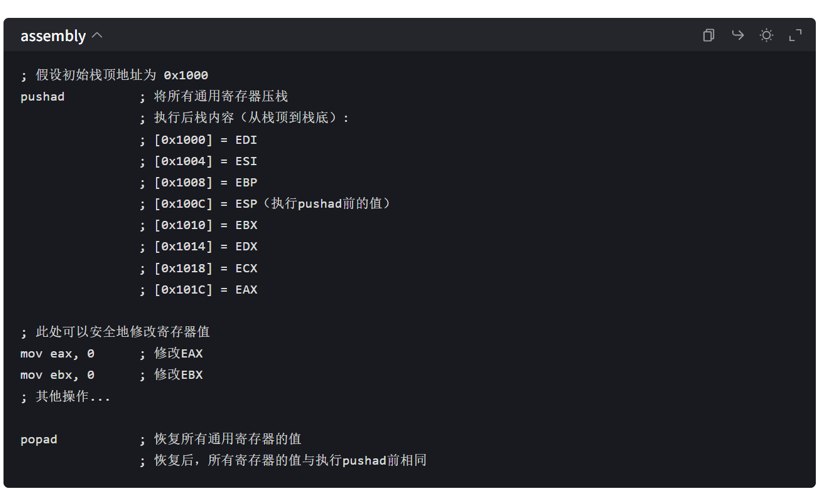
在实际应用中,pushad 和 popad 常用于函数调用或中断处理程序的开头和结尾,以此来保存和恢复寄存器状态,确保这些操作不会对调用者的寄存器值产生影响。不过要留意,这两条指令会对栈进行大量操作,所以在栈空间有限的情形下要谨慎使用。
3 POP指令(字出栈)
格式:POP 目的操作数
1 | POP AX ;恢复AX |
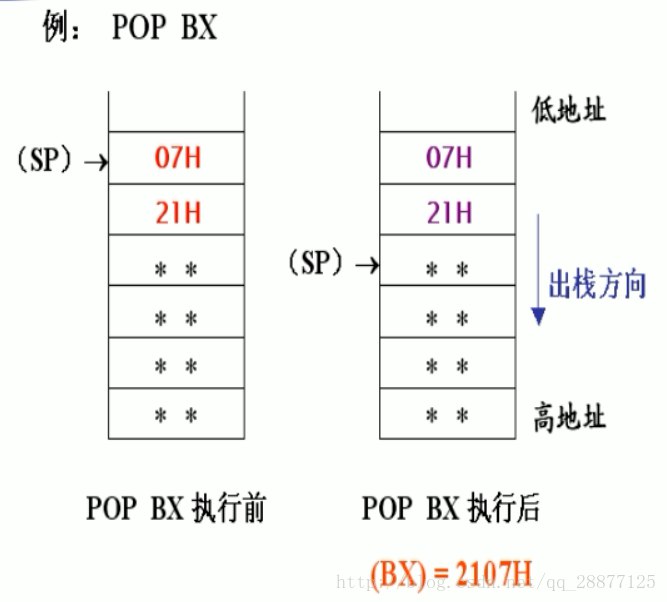
POP 指令首先将当前栈顶(ESP所指向的内存单元)的数据复制到目的操作数中,然后再增加 ESP 的值(因为出栈意味着栈顶指针向高地址回退)。如果操作数是 16 位的,则 ESP 加 2;如果操作数是 32 位的,则 ESP 加 4。
POP 指令主要有以下 2 种格式(注意:目的操作数不能是立即数):
1 | 1 POP reg/mem16 ;弹出到 16 位寄存器或内存单元 |
注意:
- 与 PUSH 相同,POP 指令不允许使用 8 位寄存器(如 AL, AH 等)。
- 目的操作数不能是立即数(你不能把栈里的数据弹到一个固定常数里)。
- POP CS 是非法的(代码段寄存器 CS 不能通过 POP 指令直接修改,这会在你下方的“堆栈操作说明”中提到)。
3.1 POPAD指令
4 栈操作说明
1、栈顶SP指向数据
因为堆栈指针SP总是指向已经存入数据的栈顶(不是空单元),所以PUSH指令时先将(SP)减2,后将内容压栈(即先修改SP使之指向空单元,后压入数),而POP是先从栈顶弹出一个字,后将堆栈指针SP加2.
2、对代码段寄存器
PUSH CS是合法的,但POP CS是不合法的。
3、堆栈特点—–FILO
因为SP总是指向栈顶,而用PUSH和POP指令存取数时都是在栈顶进行的,所以堆栈是“先进后出”或叫“后进先出”的。栈底在高地址,堆栈是从高地址向低地址延伸的,所以栈底就是最初的栈顶。
4、按字访问
用PUSH指令和POP指令时只能按字访问堆栈,不能按字节访问堆栈。
5、不影响标志
PUSH和POP都不影响标志。
6、不能用立即寻址方式
PUSH 1234H ;错误!!
这里就是对AX清零。
1 | PUSH DS |
下面就是一个保护现场的代码
1 | PUSH AX |
从键盘上键入10个字符,然后与键入字符的先后相反的顺序显示出来。( 使用 堆栈的办法)
分析: 因为堆栈是“后进先出”的,因此,利用堆栈作为输出缓冲区极易实现按逆序输出。
分配一个256个字的堆栈缓冲区,在其低字节中存放从键盘上键入的字符。我们将从键盘上接受来的10个字符依次进栈,存放在这片堆栈区里,然后再从最后一个字单元开始,弹出堆栈,即可逆序把它们显示出来。
1 | STACKS SEGMENT PARA STACK 'STACK' |
5 栈帧
进程中每个函数在运过程中都要保存自己的临时数据,这些数据就会被保存在栈上 但是不同的函数不能把数据放在一块。每个函数都要有自己的栈空间。系统给出的方案就是栈帧 栈帧指的就是一个函数在运行时使用的栈空间,它由rsp和rbp表示边界 rsp与rbp是CPU中的两个特殊寄存器,rsp叫栈顶指针寄存器,rbp叫栈底指针寄存器。两个寄存器专门用来表示stack范围
5.1 栈顶指针
作用:永远指向当前栈的“物理最顶部”(也就是栈的最后一个压入数据的地址)
栈的操作都会直接影响rsp的值
push操作:rsp会减少(因为栈地址是从高地址指向低地址,压入数据后,会向低地址移动)
pop操作:rsp会增加
5.2 栈底指针
作用:永远指着当前函数栈帧的底部 核心作用就是定位——程序找局部变量,找函数参数时,都是以rbp为参考的,比如代码buf[16],它在栈中的地址可能是rbp-0x10(rbp减去16字节),程序通过rbp的值,就能精确找到buf的地址
另外,rbp还会保存上一个函数栈帧的底部地址,这样函数执行结束后,程序能通过Saved RBP,找到上一个函数的栈帧,进而回到上一个函数继续执行
6 函数调用
函数调用本质上解决几个问题:
- 程序如何跳转到另一个函数执行;
- 函数执行完后如何回到原来的位置;
- 参数如何传递;
- 返回值如何传递;
- 栈由谁来恢复。
6.1 函数调用约定
调用约定规定了函数之间调用的基本规则,包括:
- 参数如何传递;
- 参数入栈顺序;
- 返回值放在哪里;
- 栈空间由调用者清理还是被调用者清理;
- 哪些寄存器需要保存。
比较常见的调用约定有:
6.1.1 __cdecl
__cdecl 又称 C 调用约定,是 C/C++ 中常见的调用约定。
特点:
- 参数按照从右到左的顺序入栈;
- 函数本身不清理栈;
- 栈由调用者清理;
- 返回值通常放在
EAX/RAX中; - 支持可变参数函数。
例如:
1 | printf("%d %d", a, b); |
因为参数数量不固定,所以只能由调用者清理栈。
6.1.2 __stdcall
__stdcall 是 Windows API 中常见的调用约定。
特点:
- 参数按照从右到左的顺序入栈;
- 被调用函数自己清理栈;
- 返回值通常放在
EAX/RAX中; - 不适合可变参数函数。
6.1.3 __fastcall
__fastcall 的特点是尽量使用寄存器传参,从而减少栈操作,提高调用速度。
在 32 位环境下,常见规则是:
- 前几个参数通过寄存器传递;
- 剩余参数再通过栈传递;
- 返回值通常放在
EAX/RAX中。
需要注意:不同编译器、不同平台下,fastcall 的具体规则可能不同。
6.1.4 x86-64 下的注意点
在 64 位程序中,参数通常不再全部通过栈传递,而是优先通过寄存器传递。
Linux x86-64 普通函数调用常见规则:
| 参数位置 | 寄存器 |
|---|---|
| 第 1 个参数 | RDI |
| 第 2 个参数 | RSI |
| 第 3 个参数 | RDX |
| 第 4 个参数 | RCX |
| 第 5 个参数 | R8 |
| 第 6 个参数 | R9 |
| 返回值 | RAX |
Windows x64 普通函数调用常见规则:
| 参数位置 | 寄存器 |
|---|---|
| 第 1 个参数 | RCX |
| 第 2 个参数 | RDX |
| 第 3 个参数 | R8 |
| 第 4 个参数 | R9 |
| 返回值 | RAX |
因此,分析 64 位程序时不能简单认为参数一定都在栈上。
6.2 CALL / RET 调用与返回
函数调用最核心的两条指令是:
1 | call |
call 用来调用函数。
ret 用来从函数返回。
6.2.1 call 指令
call 不是单纯跳转,它会先保存返回地址,再跳转到目标函数。
例如:
1 | call func |
可以理解为:
1 | push 下一条指令的地址 |
也就是说,call 做了两件事:
把
call后面那条指令的地址压入栈中;跳转到目标函数执行。
这个被压入栈中的地址,叫做:
1 | 返回地址 Return Address |
它表示函数执行完之后,程序应该回到哪里继续执行。
6.2.2 ret 指令
ret 用来从函数返回。
1 | ret |
可以理解为:
1 | pop rip |
也就是说,ret 会从栈顶取出一个地址,然后放入 RIP。
RIP 是当前程序正在执行的指令地址,所以一旦 RIP 被修改,程序就会跳到新的地址继续执行。
因此,ret 的作用是:
1 | 从栈顶取出返回地址,然后跳回调用函数之后的位置。 |
6.2.3 push、jmp、call、ret 的区别
| 指令 | 作用 |
|---|---|
push |
只负责把数据压入栈,不跳转 |
jmp |
只负责跳转,不保存返回地址 |
call |
先压入返回地址,再跳转到函数 |
ret |
从栈顶弹出返回地址,跳回去 |
简单理解:
1 | call = push 返回地址 + jmp 函数 |
6.2.4 CALL / RET 示例
1 | _start: |
执行流程:
1 | 1. 执行 call func |
6.2.5 CALL / RET 和 PWN 的关系
call 会把返回地址压入栈中。
ret 会从栈中取出返回地址并跳转过去。
所以如果我们能通过栈溢出覆盖返回地址,就可以控制程序执行流。
典型目标就是覆盖:
1 | [rbp + 0x08] |
因为这里通常保存着函数的返回地址。
如果返回地址被改成攻击者指定的地址,那么函数执行 ret 时,程序就会跳到攻击者控制的位置。
这就是很多栈溢出、ROP 攻击的核心基础。
6.3 栈帧核心寄存器:RSP 和 RBP
在 x86-64 函数调用体系中,有两个非常重要的栈相关寄存器:
| 寄存器 | 名称 | 作用 |
|---|---|---|
RSP |
Stack Pointer,栈顶指针 | 指向当前栈顶 |
RBP |
Base Pointer,栈基址指针 | 指向当前函数栈帧的固定基准位置 |
6.3.1 RSP:栈顶指针
RSP 永远指向当前栈顶。
当执行:
1 | push rax |
栈会向低地址增长:
1 | rsp = rsp - 8 |
当执行:
1 | pop rax |
栈会向高地址恢复:
1 | rax = [rsp] |
因此,RSP 是一个动态变化的指针。
只要发生 push、pop、call、ret、sub rsp, xxx、add rsp, xxx,RSP 都可能变化。
6.3.2 RBP:栈帧基准指针
RBP 通常用来作为当前函数栈帧的固定参考点。
函数开始时,程序会把当前 RSP 保存到 RBP 中。
之后即使 RSP 因为压栈、出栈、分配局部变量而变化,RBP 仍然保持不变。
这样就可以通过:
1 | [rbp + 偏移] |
稳定地访问参数、返回地址、Saved RBP 和局部变量。
6.4 为什么不能只用 RSP?
在函数执行过程中,程序经常需要临时压栈和出栈。
例如:
1 | push rax |
每一次 push 和 pop 都会改变 RSP。
如果只用 RSP 定位参数和局部变量,那么同一个变量相对于 RSP 的偏移会不断变化。
这会导致分析和编译都变得很麻烦。
所以函数通常会使用 RBP 作为稳定基准。
简单理解:
1 | RSP:实时变化的栈顶 |
6.5 标准汇编范式
理解函数序言和函数结语,是分析栈帧结构的基础。
6.5.1 函数序言:建立当前函数的栈帧
函数刚开始时,常见代码如下:
1 | push rbp |
含义:
1 | push rbp ; 保存调用者的 RBP,也就是 Saved RBP |
执行完之后,当前函数就拥有了自己的栈帧。
6.5.2 函数结语:恢复现场并返回
函数执行完毕后,常见代码如下:
1 | mov rsp, rbp |
含义:
1 | mov rsp, rbp ; 释放局部变量空间 |
也可以看到这种写法:
1 | leave |
其中:
1 | leave |
等价于:
1 | mov rsp, rbp |
所以:
1 | leave |
等价于:
1 | mov rsp, rbp |
6.6 RBP 静态坐标系速查表
在经典栈帧结构中,执行完函数序言之后:
1 | push rbp |
栈帧大致如下:
| 内存位置 | 存放内容 | 说明 | 危险性 |
|---|---|---|---|
[rbp + 0x18] |
参数 2 | 栈上传递的第二个参数 | 正常读取 |
[rbp + 0x10] |
参数 1 | 栈上传递的第一个参数 | 正常读取 |
[rbp + 0x08] |
返回地址 Return Address | 函数执行完后,下一条要执行的指令地址 | 极度危险,PWN 核心目标 |
[rbp + 0x00] |
Saved RBP | 调用者的 RBP 备份 | 危险,覆盖后可能导致栈帧崩溃 |
[rbp - 0x08] |
局部变量 1 | 当前函数内部变量 | 正常读写,常见溢出源头 |
[rbp - 0x10] |
局部变量 2 | 当前函数内部变量 | 正常读写 |
经典结构示意:
1 | 高地址 |
注意:
在 x86-64 程序中,前几个参数通常通过寄存器传递,不一定出现在 [rbp + 0x10]、[rbp + 0x18] 这些位置。
但是返回地址和 Saved RBP 的位置非常关键:
1 | [rbp + 0x08] 返回地址 |
在栈溢出分析中,最核心的目标通常就是覆盖返回地址。
6.7 小结
函数调用可以简单理解为:
1 | call:保存返回地址,然后跳转到函数 |
函数栈帧可以简单理解为:
1 | RSP:当前栈顶,会频繁变化 |
经典函数结构:
1 | push rbp |
PWN 中最重要的位置:
1 | [rbp + 0x08] |
因为这里保存的是返回地址。
一旦返回地址被覆盖,ret 就会跳到攻击者控制的位置。